这个 lab 是用来熟悉 xv6 和它的系统调用的,就是用它的系统调用来实现一些小工具。在实现之后要将程序加入 Makefile 里的 UPROGS 中才能执行。
sleep (eazy)
就是调用已经实现的系统调用 sleep (具体实现在 sysproc.c#sys_sleep 中 ) 来实现即可,非常简单。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
int
main(int argc, char *argv[])
{
if (argc < 2) {
printf("must enter a sleep time!\n");
exit(0);
}
int time = atoi(argv[0]);
sleep(time);
exit(0);
}
|
pingpong (eazy)
使用 pipe 系统调用创建管道,用 fork 系统调用创建子进程,然后两个进程使用这个管道进行通信,使用 read/write 系统调用对 pipe 进行读写即可;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
int
main(int argc, char *argv[])
{
int send[2], recv[2];
if (pipe(send) < 0 || pipe(recv) < 0) {
printf("there is a problem when create a pipe!\n");
exit(0);
}
if (!fork()) {
char c;
read(send[0], &c, 1);
int pid = getpid();
printf("%d: received ping\n", pid);
write(recv[1], "a", 1);
} else {
write(send[1], "a", 1);
char c;
read(recv[0], &c, 1);
int pid = getpid();
printf("%d: received pong\n", pid);
}
exit(0);
}
|
primes (moderate/hard)
这个是利用 fork 和 pipe 来实现并发的处理质数(除了 1 和 它本身,不能被整除的数)。一开始我还没有懂什么意思,看了这张图之后还是没有搞懂:
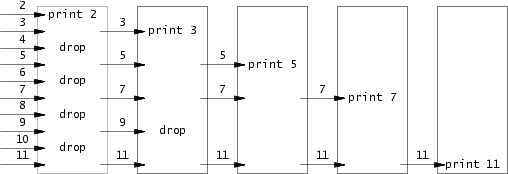
后来看到一个 golang 版本的实现才明白是什么意思,也就是 root 父进程向一个通道中发送 2-35,并且 fork 出一个子进程,将这个通道传递给子进程,子进程从管道中读取出一个数,比如当前情况下这个数就是 2,它是一个质数(通道中的第一个数一定是质数,因为它没有被任何比它小的数给过滤掉),那么就打印。
接着这个子进程,再创建一个通道并 fork 一个子进程,然后将父进程通道中剩下的 3-35 都对刚刚取出来的质数 2 取模,如果不等于 0,表示起码不能被 2 整除,就将它放到新创建的通道中给它的子进程处理(看看它能不能被剩下的数整除)。
循环往复直到有一个子进程在通道里读不出东西了,这个时候表示 2-35 的所有质数都被找到了,就返回。要注意的是,每个进程都要等待它的子进程退出之后才能退出,所以要调用 wait 等待子进程退出。并且对于不再使用的通道要及时将其关闭,否则程序算不到 35 就会使 xv6 资源不足。关闭通道分关闭读端和写端,父进程对自己创建的通道只需要写而不需要读,所以它可以将读端先关闭,写完之后再将写端关闭,而子进程对于收到的通道只需要读不需要写,所以在收到之后,它可以先关闭写端,读完后再关闭读端。父进程不能再创建完后就关闭,而要在 fork 之后再关闭,因为如果先关闭了,那么子进程再持有到这个通道的文件描述符后,会发现通道的读端是关闭,无法读取数据,会被阻塞(卡了我好久)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
void processor(int *pipeline)
{
close(pipeline[1]);
int status;
int prime;
int read_len = read(pipeline[0], &prime, sizeof(int));
if (read_len == 0)
{
close(pipeline[0]);
return;
}
printf("prime %d\n", prime);
int out[2];
pipe(out);
if (!fork())
{
processor(out);
exit(0);
}
else
{
close(out[0]);
int num;
while (read(pipeline[0], &num, sizeof(int)) != 0)
{
if (num % prime != 0)
{
write(out[1], &num, sizeof(num));
}
}
close(out[1]);
close(pipeline[0]);
wait(&status);
}
}
int main(int argc, char *argv[])
{
int status;
int pipeline[2];
pipe(pipeline);
if (!fork())
{
processor(pipeline);
exit(0);
}
else
{
close(pipeline[0]);
int num = 2;
while (1)
{
write(pipeline[1], &num, sizeof(num));
num++;
if (num > 35)
{
close(pipeline[1]);
break;
}
}
wait(&status);
}
exit(0);
}
|
find (moderate)
find 是用来找出在文件夹中所有的指定名称的文件。
可以参考 user/ls.c 来看如何读取文件夹,并且使用递归来读取子文件夹(不用递归 “.” 和 “..” ,否则会爆栈)。使用 strcmp() 来比较字符串。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
char *
fmtname(char *path)
{
char *p;
for (p = path + strlen(path); p >= path && *p != '/'; p--)
;
p++;
return p;
}
void find(char *path, char *filename)
{
char buf[512], *p;
int fd;
struct dirent de;
struct stat st;
if ((fd = open(path, 0)) < 0)
{
fprintf(2, "find: cannot open %s\n", path);
return;
}
if (fstat(fd, &st) < 0)
{
fprintf(2, "find: cannot stat %s\n", path);
close(fd);
return;
}
if (strlen(path) + 1 + DIRSIZ + 1 > sizeof buf)
{
printf("ls: path too long\n");
}
strcpy(buf, path);
p = buf + strlen(buf);
*p++ = '/';
while (read(fd, &de, sizeof(de)) == sizeof(de))
{
if (de.inum == 0)
continue;
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
if (stat(buf, &st) < 0)
{
printf("ls: cannot stat %s\n", buf);
continue;
}
if (st.type == 2)
{
if (!strcmp(fmtname(buf), filename))
{
printf("%s\n", buf);
}
}
else if (st.type == 1)
{
if (!strcmp(de.name, ".") || !strcmp(de.name, ".."))
{
continue;
}
find(buf, filename);
}
}
close(fd);
}
int main(int argc, char *argv[])
{
if (argc < 3)
{
exit(0);
}
find(argv[1], argv[2]);
exit(0);
}
|
xargs (moderate)
xargs 从标准输入中读取数据,将每一行当作参数添加到 xargs 后面的程序中当作参数,比如:
echo hello too | xargs echo bye -> echo bye hello too.
| 符号表示通过管道将数据发送到程序中,所以我们读数据的时候只要使用 read 系统调用在标准输出中读取就可以了,标准输出的 fd 编号为 0。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
#define MAXARGS 10
int main(int argc, char *argv[])
{
int buf_idx, read_len;
int status;
char buf[512];
char* args[MAXARGS];
int i;
for (i = 1; i < argc; i++) {
args[i-1] = argv[i];
}
while (1)
{
buf_idx = 0;
while (1)
{
read_len = read(0, &buf[buf_idx], sizeof(char));
if (read_len <= 0 || buf[buf_idx] == '\n') {
break;
}
buf_idx++;
}
if (read_len == 0) {
break;
}
buf[buf_idx] = '\0';
args[argc-1] = buf;
if (!fork()) {
exec(args[0], args);
exit(0);
} else {
wait(&status);
}
}
exit(0);
}
|
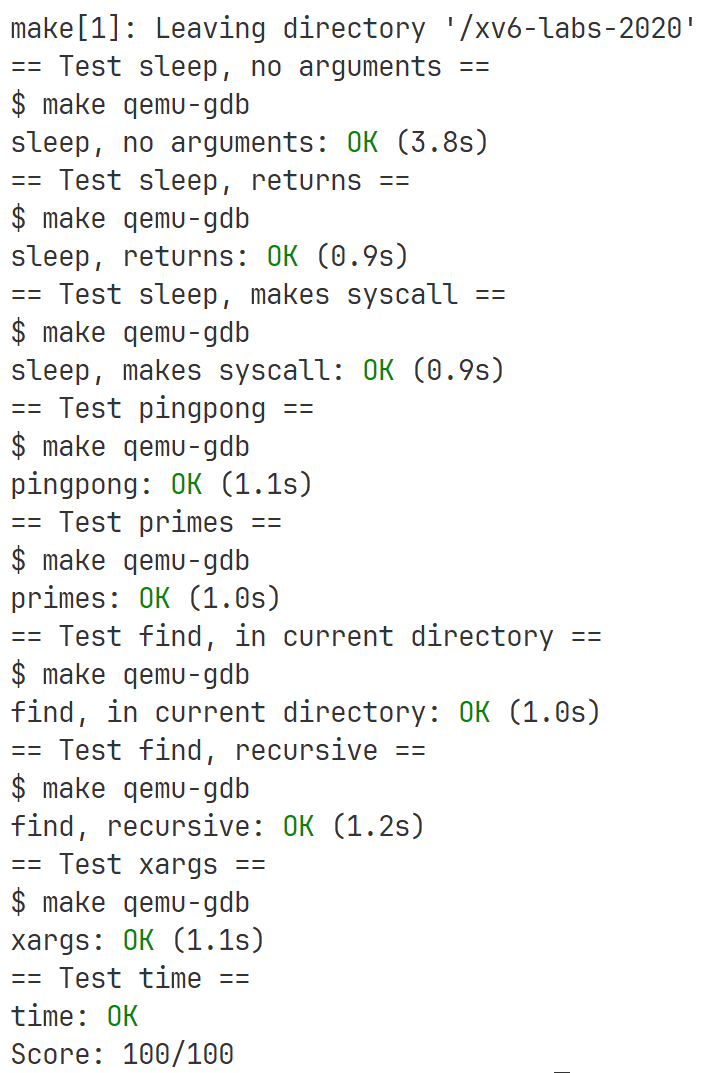
执行结果