项目 2 是实现一个可拓展的哈希索引,它包含一个 directory_page,其中存储了指向 bucket_page 的指针,而数据就存储在 bucket_page 中。这些 page 都会存储在之前写的缓存池中。
该哈希索引要支持满/空桶的拆分/合并,并且也要支持目录的拓展和收缩(Extendible)。
本次项目有三个任务,分别是:
- Page Layouts
- Extendible Hashing Implementation
- Concurrency Control
Extendible Hash Index
要完成这个项目首先一定要把 Extendible Hash Index 的流程弄清楚,否则写起来会缺胳膊少腿。可以阅读这篇文章了解先算法流程:
https://www.geeksforgeeks.org/extendible-hashing-dynamic-approach-to-dbms/
,后文的内容默认读者都是已经看过这篇教程,这篇图文教程写的非常清楚,但是并没有写如何收缩,剩下的细节在后面实现中提到。
TASK #1 - PAGE LAYOUTS
这个任务就是要实现 directory_page 和 bucket_page,分别来存储哈希表的目录和数据。
要通过 Task #1 ,两种页都只需要实现部分方法即可:
- Bucket Page: - Insert - Remove - IsOccupied - IsReadable - KeyAt - ValueAt
- Directory Page: - GetGlobalDepth - IncrGlobalDepth - SetLocalDepth - SetBucketPageId - GetBucketPageId
但为了看起来更有整体性,所以在写的时候就将整个 Extendible Hash Index 所需要的东西全部写上了。
HASH TABLE DIRECTORY PAGE
概念
GlobalDepth:
当 Extendible Hash Index 进行 GetValue、Insert、Remove 时,GlobalDepth 用于确定这个 key 对应的 directory_index 在哪,具体来说就是取这个 key 经过哈希之后的 低 GlobalDepth 位来确定 directory_index。比如当前要插入的 key 哈希之后得到的结果是 00110,GlobalDepth 是 3,那么取低 3 位也就是 110,那么 directory_index 就等于 6。但项目中给出的公式是:DirectoryIndex = Hash(key) & GLOBAL_DEPTH_MASK, GLOBAL_DEPTH_MASK 得求出来,其实它就等于 GloablDepth 这么多个 1,所以 GetGlobalDepthMask 函数就很好实现了:
1 | return (1 << global_depth_) - 1; // 得到 GlobalDepth 这么多个 1. |
LocalDepth:
LocalDepth 并不与 directory_index 相关,而是与 bucket 相关。我们会根据LocalDepth 和 GlobalDepth 的关系来决定当发生 bucket_page 溢出,或者 bucket_page 为空时需要干的事情(具体要到 Extendible Hash Table 的实现)。GetLocalDepthMask 的实现方式跟 GetGlobalDepthMask 一样。
SplitImageIndex:
这个指的是 bucket_page 分裂之后,它分裂出来的那个 bucket_page 的 directory_index,只要将当前 bucket的 directory_index 中 LocalDepth 对应的那个位取反即可。比如说 directory_index 是 001,LocalDepth 为 2,那么它的 split_image_index 就是 011,可以通过异或运算来实现:
1 | return bucket_idx ^ (1 << (local_depth - 1)); |
实现
Mask 和 SplitImageIndex 如何求上面已经写了,还剩下就是 IncrGlobalDepth、DecrGlobalDepth、Size。
IncrGlobalDepth:当 GlobalDepth 增加时,就是目录需要扩容了,GlobalDepth 增加 1,目录的容量就增加一倍,所以实现这个函数时,我们要把目录扩容前的 bucket 分布情况拷贝一份到扩容后的位置,也就是此时一个 bucket_page 是有多指针指向它的。注意此时数据还并未进行迁移,因为新的 bucket_page 还没插进来,只是先把目录拓展。
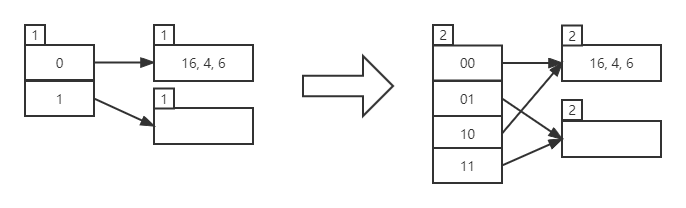
DecrGlobalDepth:当 GlobalDepth 减少时,就是目录需要缩小了,GlobalDepth 减少 1,目录的容量就减少一倍,但注意只有当所有的 LocalDepth 都小于 GlobalDepth 时,才能减少 GlobalDepth,如果能够减少,我们只需要 global_depth_– 即可,因为 GlobalDepth 减少了,后面的无用位置其实已经访问不到了。
Size:返回当前目录的长度,GlobalDepth 有多少位,目录长度就是 2 的多少次方,即 1<<global_depth_。
HASH TABLE BUCKET PAGE
概念
实现 bucket_page 同样也需要用到很多位运算,因为 occupied_ 数组和 readable_ 数组都是 char 类型的数组,而一个 char 是一个字节,即 8 比特,所以可以标识 bucket_page 中八个位置的情况,我们要用 bucket_index 在 char 数组中找到那个对应的比特。
occupied_ 数组的含义:如果 array 的第 i 个索引曾经有被占用过,那 occupied_ 数组的第 i 个比特位就是1。注意:一旦设置为 1,那么这个位置之后就不会再变成 0 了,除非 bucket_page 内容被清空。
readable_ 数组的含义:如果 array 的第 i 个索引当前存储了可读的值,那 readable_ 数组的第 i 个比特就是 1 。
实现
首先要实现的是 IsOccupied、SetOccupied、IsReadable、SetReadable 函数。我选择的是用除法的方式来确定索引对应的比特位:
1 | const auto [char_pos, bit_pos] = std::div(bucket_idx, CHAR_BIT_SIZE); |
char_pos 即 char 数组中的第几个字符,bit_pos 则是该字符中的第几位是我们要找的位。假设 ch 为一个字符。
判断找出来的位是否为 1:
1 | ((ch >> bit_pos) & 1) == 1; |
将某一位设置为 1:
1 | ch |= (1U << bit_pos); |
将某一位设置为 0:
1 | ch &= ~(1U << bit_pos); |
接下来就可以实现 GetValue、Insert、Remove 了:
Insert:
插入是可以插入 key 重复,但不能插入 key 和 value 同时重复的值的,所以不能找到一个空位就插进去,因为后面可能还有 KV 都重复的条目,要全都检查一遍。
Remove:
找到 KV 都符合的那个条目,将 readable_ 数组的这个位置设置为 0 即可。
GetValue:
将所有符合 key 的条目都放进 result 数组中,再返回 result 是否为空即可。
Remove 和 GetValue 有个可以优化的点就是一旦到了一个位置的 occupied 为 0,那么就可以停止遍历了,因为后面已经没有数据。
TASK #2 - HASH TABLE IMPLEMENTATION
概念
现在开始可以着手实现可拓展哈希表了,我们要在刚刚之前实现的 bucket_page 和 directory_page 的基础上实现 GetValue、Insert、Remove。如果看了前文提到的博客,应该大致流程都已经了解了,本文再对具体的实现步骤和细节做一个总结。
实现
构造函数:
我在构造函数中新建了一个 directory_page 和两个 bucket_page,并将 GlobalDepth 设置为 1,再将这两个 bucket_page 的 id 放进目录中,再测试中将所有数据删除后就会恢复到现在的状态,GlobalDepth 和 LocalDepth 最小为 1。记得 pin 过的页一定要及时的 unpin。
将 新创建的 Page 对象转成 directory_page 或 bucket_page 可以用下面这种方式:
1 | auto dir_page = reinterpret_cast<HashTableDirectoryPage *>(buffer_pool_manager_->NewPage(&this->directory_page_id_)->GetData()); |
在实现 FetchDirectoryPage 和 FetchBucketPage 时可以用同样的方法。
GetValue:
这个函数的实现没有什么好说,将 directory_page 和 key 所在的 bucket_page 拉出来调用查询方法即可。
Insert:
Insert 的实现细节很多,有非常多需要注意的地方,具体的实现步骤如下:
- 将 directory_page 和 key 所在的 bucket_page 拉取出来。
- 尝试进行插入,若插入成功则直接返回 true,否则进行步骤 3 。
- 判断 bucket_page 是否已满,如果未满还是插入失败那么只能是已经重复,返回 false,否则进行步骤 4 。
- 如果 bucket_page 已满,但是这时候不能直接进行分裂,因为就算是满了的情况,也有可能已经重复,如果这时候分裂就会导致插入错误(我因为这个错误卡了很久),还要再检查一遍是否重复。
- 这个时候将刚刚用到的页 unpin,进入 split insert 阶段。
- 将需要分裂的 bucket_page 的 LocalDepth 加 1,判断 LocalDepth 是否大于 GlobalDepth,如果大于则将 directory 进行扩容,即调用之前实现的 IncrGlobalDepth 函数。
- 获取到需要分裂的 bucket_page 的 SplitImageIndex,并为这个兄弟 bucket 创建一个新的页(注意创建了页之后就不要再 Fetch 了),取出原 bucket_page 中的所有数据,再将数据重新散列到这两个页中。
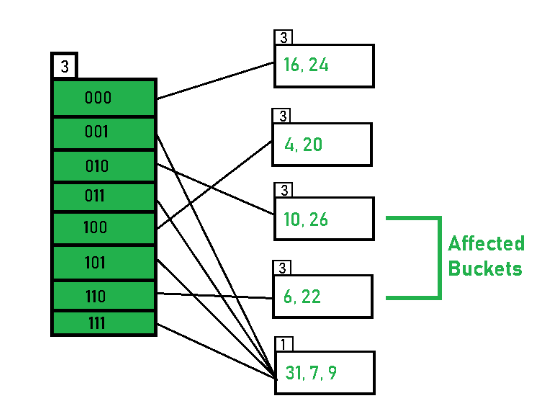
- 这里有一个需要注意的地方,一个 bucket 分裂之后,仍然有可能有多个指针指向它,如下图所示。当我们往第五个 bucket_page 里再插入一个数据时,它进行分裂后,它自身和分裂出来的那个页仍然各自都有两个指针指向它,所以我们不止要设置 SplitImageIndex 那个位置的指向新分裂出来的页,和它同级的另一个指针也需要指向这个页,并且 LocalDepth 也要更新成一样的。
- 最后再次尝试插入需要插入的那个值,这里要重新通过哈希和 mask 来获取应该插入的地方。
- 将使用到的页 unpin 并返回。
Remove:
- 将 directory_page 和 key 所在的 bucket_page 拉取出来。
- 尝试进行删除,如果删除失败则直接返回 false,否则将使用到的页 unpin 并进行步骤 3,调用 Merge 函数 。
- 再次拉取 directory_page 和 key 所在的 bucket_page,检查 bucket_page 是否为空,如果不为空则 unpin 并返回,否则进行步骤 4 。
- 如果该 bucket_page 的 LocalDepth 小于等于 1,或 它不等于它 SplitImage 的 LocalDepth,则 unpin 并返回,否则进行步骤 5 。
- 将该 bucket_page 的 SplitImage 的 LocalDepth 减 1,并将 LocalDepth 减 1 后的所有同级 bucket 的 LocalDepth 和指向的 bucket_page 都设置为 SplitImage 。这一步跟 Insert 的步骤 8 类似。
- 一定要先 unpin 该 bucket_page ,然后再将这个页删除。
- 将使用到的页 unpin 并返回。
Extendible Hash Table 到这里就已经可以通过除了并发控制测试之外的所有测试了。
TASK #3 - CONCURRENCY CONTROL
最后我们要进行并发控制,给页上锁的方式项目说明中已经详细写到了,这里就不再多做说明,只说一下加锁的思路。
GetValue:
table_latch_ 和 bucket_page 的锁均上读锁即可。
Insert:
插入阶段,table_latch_ 只需要上读锁即可,但是对 bucket_page 要上写锁,因为此时只对一个 bucket_page 进行修改。
SplitInsert:
这个阶段因为目录也有可能被修改,所以两个都需要上写锁。
Remove:
跟 Insert 同理。
Merge:
跟 SplitInsert 同理。
总结
项目二整体还是非常难的,首先一定要认真搞清楚 Extendible Hash Table 到底是什么再来动手,否则从一开始就会理解不了。然后用到了很多位运算,如果之前没什么经验的话也需要琢磨一下。现在这个版本等整个项目写完了再考虑优化一下吧,提交上去发现发现花了三十几秒。